
Big Data ist ein wichtiges Thema. Das zeigt schon eine Studie der Bitkom. Der Verband hat 2018 über 600 Unternehmen zu Trendthemen befragt und folgende Ergebnisse festgestellt:
- 57 Prozent planen Investitionen in Big Data oder sind bereits in der Umsetzung
- Die fünf Top Themen sind Big Data (57%), Industrie 4.0 (39%), 3D-Druck (38%), Robotik (36%) und VR (25%)
- Aber: Neue Konzepte und Möglichkeiten wie Künstliche Intelligenz und Blockchain werden bislang nur selten genutzt
Lesetipp: Was ist Big Data?
Umsetzung von Big Data nur zögerlich
Laut der Studie werden die Potentiale von Big Data nur zögerlich genutzt. Gründe sind laut der Studie die Anforderungen an Datenschutz (63%) und die technische Umsetzung (54%) sowie fehlenden Fachkräfte (42%).
Lesetipp: Was ist ein Data Scientist
Ich befasse mich aktuell mit der technischen Umsetzung. Um Big Data wirklich sinnvoll zu nutzen, müssen zahlreiche technische Voraussetzungen geschaffen werden. Ich möchte dazu ein Praxisbeispiel geben, welches als Impuls für die Praxis dienen soll.
Praxisbeispiel: Aufbau eines Data Lake
Ich bin durch meinen Job oft in Kundenprojekten, welche Big Data Architekturen aufbauen wollen. Ich habe mir im folgenden aus der Mehrheit der Projekte eine Art Blaupause gemacht. Diese möchte ich Ihnen heute vorstellen. Um das Beispiel anschaulicher zu machen schreibe ich das ganze als Fallstudie.
Ausgangssituation
Der Kunde ist eine fiktive große Bank. Aus verschiedenen Quellen z.B. Datenbanken und Datenströmen kopiert sich das System Daten in Rohform in eine Staging Area. Ein Datenstrom ist ein kontinuierlicher Fluss von Datensätzen, dessen Ende meist nicht im Voraus abzusehen ist z.B. die Überweisungen einer Bank oder Einzahlungen auf ein Konto sowie die das Pulsmessgerät im Krankenhaus oder die Temperaturmessung einer Wetterstation. Das Staging dient dazu, dass die Rohdaten in aktueller Form mit Zeitstempel abgespeichert sind. Vorteil ist, dass diese im Fall eines Verlust der externen Datenquelle noch da sind.
Die Staging Area speichert die Daten auf verschiedenen Festplatten durch ein sicheres und redundantes Speicherformat. Die Daten werden durch diverse (selbstentwickelte) Algorithmen in ein einheitlichen Format in der Norming Area erneut abgespeichert. Mithilfe von SQL Abfragen werden Daten in das CSV Format exportiert und in Sharepoint abgespeichert. Aus diesem fertigen zahlreiche externe IT-Consultants wöchentlich Berichte in Powerpoint und Excel an. Die Berichte sind in Ordner sortiert mit den Quelldaten auf Sharepoint zu finden.
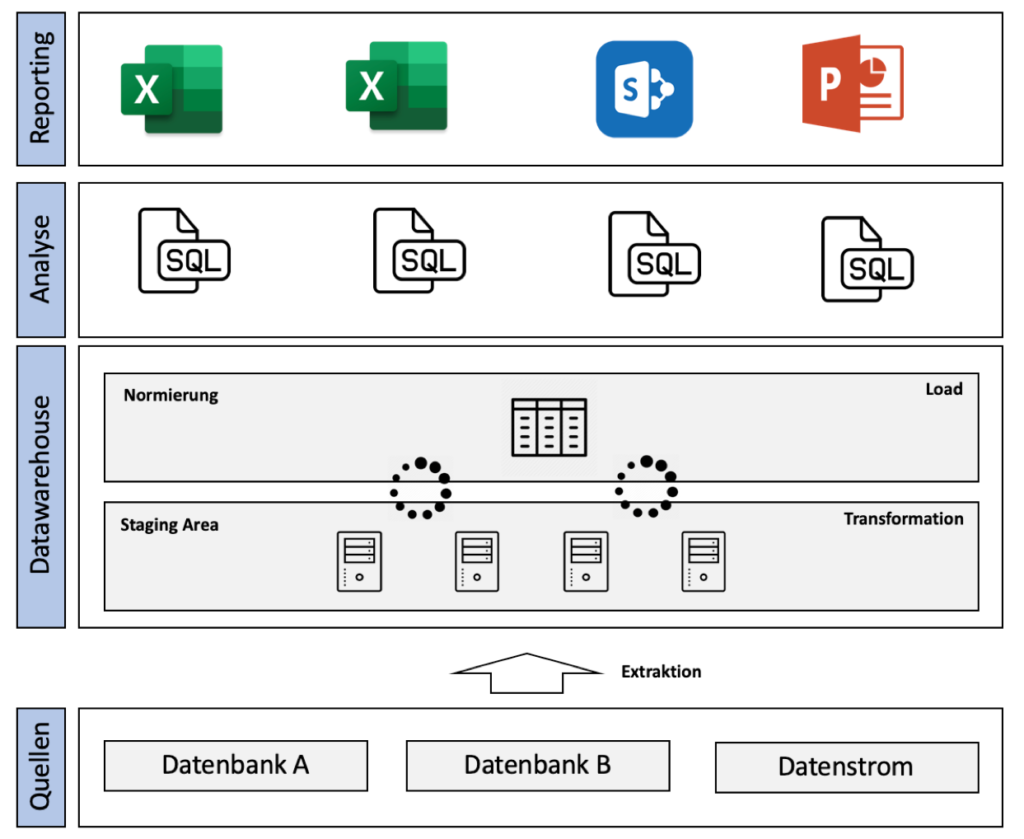
Zusammenfassung der Architektur:
- Daten kommen aus verschiedenen Quellsystemen
- Immer am Tagesende werden die Daten verarbeitet, normiert und aufgenommen
- Verschiedenste Abfragen werden gemacht
- Reports werden wöchentlich durch externe Dienstleister (MS Office und Sharepoint als Ablageort) generiert
Nun komme wir ins Spiel. Der Kunden hat mein Team und mich mit der Konzeption einer neuen Architektur beauftragt. Gründe dafür waren:
- Hoher Aufwand der Berichte
- Wenig Flexibilität (speziell AD-HOC Anfragen)
- Keine versionierten Rohdaten
- Hohe Kosten der externen Dienstleister
- Anforderungen bezüglich BCBS239 und MARISK nicht mehr umsetzbar (Grundsätze für die effektive Aggregation von Risikodaten und die Risikoberichterstattung)
Zielsituation
Nun haben wir anfangen die Architektur des Kunden neu aufzusetzen. Wir haben im ersten Schritt die Ladeprozesse überarbeitet. Auf der einen Seite haben wir durch Batch-Ladeprozesse täglich (nachts) neue Daten unseren Lake geladen. Auf der anderen Seite werden die Datenströme im Gegensatz dazu kontinuierlich geladen.
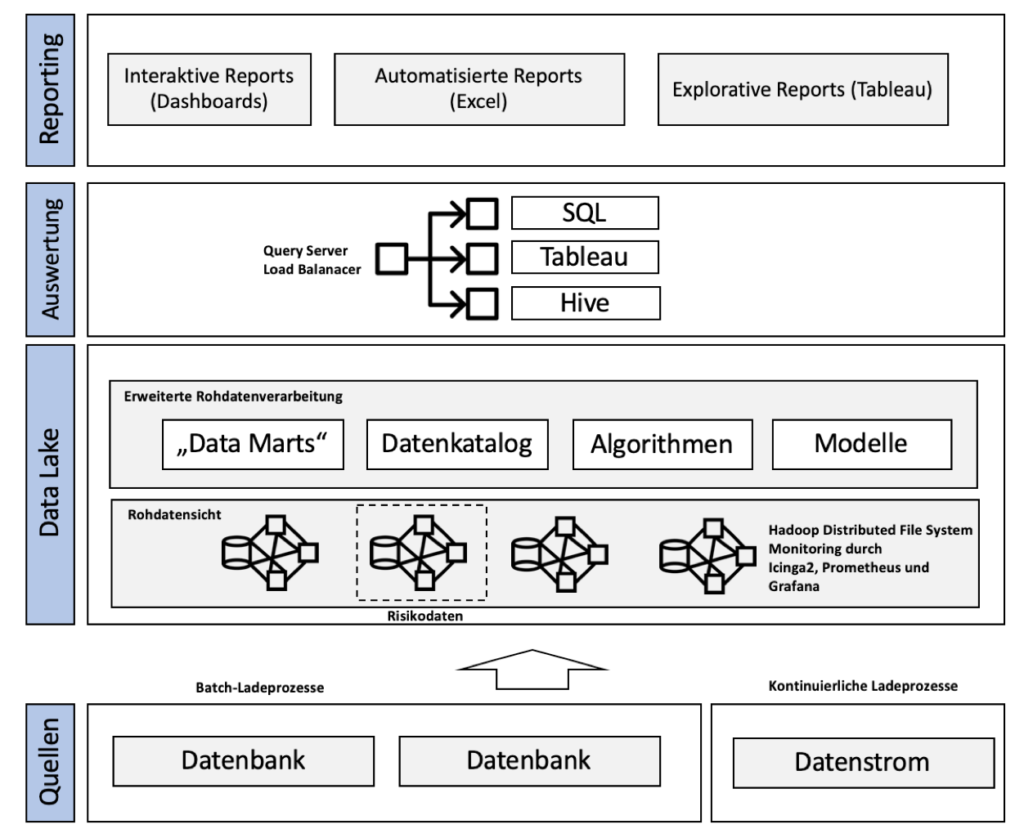
Quellen
All diese Daten werden auf Festplatten abgespeichert und bekommen einen Versionisierungstempel. Dieses Konzept nennt sich Data Lake sowie Metadatenmanagement. Beim Data Lake sprechen wir von einen sehr großen Datenspeicher, also einer überdimensionalen Festplatte, die Daten aus den unterschiedlichsten Quellen in ihrem Rohformat aufnimmt.
Data Lake
Der Data Lake half uns sogenanntes Data Lineage durchzuführen. Stellen Sie sich das so vor: Data-Lineage ist wie eine Patientenakte mit wichtigen Informationen darüber, wann Daten erstellt sind bis hin zum aktuellen Datenalter und Änderungen. Die Darstellung gibt es meist sehr übersichtlich in Diagrammform.
Vorteil: Wir konnten bei Berichten genau nachweisen auf welcher Datengrundlage wir diese zum Zeitpunkt X angefertigt haben. Mithilfe von Data Lineage konnten wir anschließend auch die Änderung der Daten verfolgen.
Grundlage unseres Data Lake war Hadoop mit modernen Monitoring durch Prometheus, Grafana und Icinga 2. Wir haben dazu hochverfügbare Cluster aufgebaut. Beim Hadoop Distributed File System (HDFS) handelt es sich um ein verteiltes Dateisystem, welche durch einen MapReduce-Algorithmus komplexe und rechenintensive Aufgaben in viele kleine Einzelteile auf mehrere Rechner aufzuspalten kann. Somit sind Auswertungen auf Basis der Rohdaten zur Laufzeit möglich.
Übrigens: Aufgrund der Richtlinien der MARISK und BCBS 239 für Banken haben wir Risikodaten in ein eigenes Cluster geladen. Dieses Cluster konnte nur durch autorisierte Personen abgerufen werden. Bedenken sind, dass im Lake so viele Querschlüsse durch die Kombination von Daten gezogen werden, dass wir bestimmte Daten aus Sicherheitsgründen extra gespeichert haben.
Nun wollen wir die Rohdaten aus dem Lake auch verarbeitet. Zuerst haben wir die Daten von standardisierte Reports, welche jede Woche gebraucht werden oder von bestimmten Abteilungen angefordert werden als Data Marts auf extra Festplatten kopiert. So konnten wir die Zugriffskontrolle gewährleisten und die Performance verbessern. Wir hatten damit feste (dauerhafte) und flüchtige Data Marts (projektbasiert).
Limitierung: Mir ist klar, dass Data Marts ein Konzept des Data Warehouse sind aber in unserem Kontext waren diese echt hilfreich, da wir nicht zu 100% auf den Data Lake setzen können.
Mithilfe von neuen Algorithmen (interne Algorithmen des Kunden) haben wir eine Normierungen der Daten zur Laufzeit oder für die Datenmarts vorgenommen. Auch haben wir mithilfe einer Software versucht durch Bildung von Clustern durch künstliche Intelligenz neue Erkenntnisse und Modelle aus den Daten zu sammeln. Wir haben beispielsweise Daten korrelieren lassen oder Ausreise untersucht. Dies hat ein spezieller KI Dienstleister übernommen. Ein weiteres Elemente ist der Datenkatalog. Der Datenkatalog ist ein Katalog von Metadaten und zeigt die Darstellungsregeln für alle Daten und die Beziehungen zwischen den verschiedenen Daten.
Hinweis: Der Datenkatalog hat die wichtige Funktion, dass ohne Zugriff auf den Katalog zwischen gewissen personenbezogenen Risikodaten keine Beziehung hergestellt werden kann.
Auswertung
Nun kommen wir zur Logik der Auswertung. Wir wollen sicherstellen, dass die verschiedenen Stakeholder im Unternehmen so drei Standards einfach an unseren Query Server senden können. Die Anfragen werden durch einen Load Balancer sinnvoll verteilt und durch eine Zugriffskontrolle auch geschützt. Die drei Standards sind:
- SQL
- Hive (SQL-ähnliche Hadoop kompatible Sprache)
- Tableau (Software-Tool)
Reporting
Nun kommen wir zur eigentlichen Reporterstellung für den Enduser. Wir haben dazu unsere drei Gruppen im Unternehmen. Diese sind:
- das klassische Controlling,
- die Fachabteilungen (und Projektleiter) und
- die Data Scientists.
Alle drei Rollen können je nach Zugriffskontrolle Anfragen an unseren Query Server senden. Für jede Rollen gibt es eine mögliche Auswertungen:
- Feste und automatisierte Reports für das Controlling,
- Interaktive und individualisierbare Dashboards für die Fachabteilungen und
- Explorative Reports in Tableau für die Data Scientists.
Zusammenfassend gibt es die standardisierten automatischen Reports, welche wir in CSV oder Excel anschauen konnten sowie für den individuellen Echtzeitreport interaktive Dashboards durch eine eigene Software. Weiterhin hatte ein Team aus Data Scientist das Ziel mithilfe von Tableau neue Erkenntnisse aus Daten (explorative Reports) zu gewinnen.
Zusammenfassung der neuen Architektur:
- Rohdaten werden in die Datenhaltung geladen (Hadoop Cluster)
- Map-Reduce Algorithmus verteilt die Auswertung intelligent
- Auswertungen erfolgen direkt aus der Rohdatenschicht
- Transformation immer erst zur Laufzeit
- Datenkatalog zur Speicherung von Datenbeziehungen
- Modellbildung durch KI
- Query Server erlaubt diverse Anfragen diverser Sprachen
- Data Lineage zur Versionierung der Daten
- Automatisierte Reports und interaktive/explorative Dashboards durch eine Eigenentwicklung
Fazit
Big Data kann Unternehmen maßgeblich verändern und steht ganz oben auf der Agenda. Die Hürden sind jedoch vor allem die technische Umsetzung und Aufbereitung der Daten. Klassische Konzepte sind nicht mehr fähig solche Daten aufzuwerten und Unternehmen sind durch gesetzliche Anforderungen unter Druck Daten gezielt rechtssicher zu speichern und aktuelle Berichte zu liefern.
In dieser Fallstudie habe ich ein Beispiel zur technischen Umsetzung gegeben, welches als Impuls für die Praxis dienen kann. Ich habe in der Fallstudie einen Data Lake aufgebaut und diverse bekannte Konzepte wie Hadoop verwendet. Meine Erfahrung zeigt, dass die korrekte Umsetzung der Konzepte helfen kann die Potentiale Big Data möglich zu machen. Es gilt aus den Daten sinnvolle Berichte und Erkenntnisse zu ziehen.
Lesetipp: Vorteile von Big Data
Bildquelle: Geschäft Foto erstellt von mindandi – de.freepik.com
Genderhinweis: Seit Anfang 2022 achte ich darauf, dass ich immer genderneutrale Formulierungen verwende. Vor 2022 habe ich zur leichteren Lesbarkeit die männliche Form verwendet. Sofern keine explizite Unterscheidung getroffen wird, sind daher stets sowohl Frauen, Diverse als auch Männer sowie Menschen jeder Herkunft und Nation gemeint. Lesen Sie mehr dazu.Rechtschreibung: Ich führe diesem Blog neben dem Job und schreibe viele Artikel in Bahn/Flugzeug oder nach Feierabend. Ich möchte meine Gedanken und Ansätze als Empfehlungen gerne teilen. Es befinden sich oftmals Tippfehler in den Artikeln und ich bitte um Entschuldigung, dass ich nicht alle korrigieren kann. Aber Sie können mir helfen: Sollten Sie Fehler finden, schreiben Sie mich gerne an! Lesen Sie mehr dazu.
Helfen Sie meinem Blog, vernetzen Sie sich oder arbeiten Sie mit mir
Sie haben eigene, interessante Gedanken rund um die Themenwelt des Blogs und möchten diese in einem Gastartikel auf meinem Blog teilen? – Aber gerne! Sie können dadurch Kunden und Fachkräfte ansprechen.Ich suche aktuell außerdem Werbepartner für Bannerwerbung für meinen Blog. Sollte es für Sie spannend sein Fachkräfte oder Kunden auf Ihre Seite zu leiten, dann bekommen Sie mehr Informationen hier.
Tipp: Ich vergebe auch über den Blog eine gratis Zertifizierung zum Digital & Agile Practioner!
Vernetzen Sie sich in jedem Fall auf Xing oder LinkedIn oder kontaktieren Sie mich direkt für einen Austausch, wenn Sie gleich mit mir ins Gespräch kommen wollen. Werfen Sie auch einen Blick in meine Buchvorschläge zur Digitalisierung, vielleicht wollen Sie mir auch ein Buch empfehlen?
Ich arbeite gerne mit Unternehmen zusammen. Sie können mich ebenfalls gerne bezüglich folgender Punkte anfragen:
- Sehen Sie übersichtlich alle Möglichkeiten zur Zusammenarbeit
- Halten von Vorträgen zu Arbeit, Führung und Agilität
- Veröffentlichung von Gastartikeln
- Content Marketing & Texterstellung
- Workshops und Seminare
- Softwareentwicklung für Unternehmen
- Whitepaper für B2B Leads
- IT-Administation AWS, Kubernetes, Ansible, Cloud und Terraform
- Public Relations (PR) für Unternehmen
- Influencer Marketing
- Whitepaper für B2B Leads

Ich blogge über den Einfluss der Digitalisierung auf unsere Arbeitswelt. Hierzu gebe ich Inhalte aus der Wissenschaft praxisnah wieder und zeige hilfreiche Tipps aus meinen Berufsalltag. Ich bin selbst Führungskraft in einem KMU und Ich habe berufsgeleitend an der Universität Erlangen-Nürnberg am Lehrstuhl für IT-Management meine Doktorarbeit geschrieben.




